There’s little doubt that 2021 has been the year of the software supply chain attack, with many notable breaches that include Solarwinds (technically a Dec. 2020 event, but most fallout occurred in 2021), Kaseya, CodeCov, PHP, and more. In a software supply chain attack, bad actors look to compromise an organization’s software delivery pipeline. From there they can tamper with code, uncover hardcoded secrets, adjust security controls, and more.
What makes such software supply chain attacks so dangerous is that they’re both a breach against the software provider, and if attackers compromise the software with malicious code, then the breach can extend downstream to its customers as well. A recent Cyentia Institute study found that breaches extending downstream to multiple parties, including supply chain breaches, are 10x more costly than traditional breaches.

Unfortunately, such attacks are becoming more prevalent as perpetrators have shifted their focus from production applications to breaching and weaponizing software supply chains. A new attack, dubbed Trojan Source, is the latest example of how attackers are innovating and increasing the sophistication of their approaches.
A Clever New Technique to Tamper with Code
Traditionally, if an attacker wanted to inject malicious code into software, they might try to sneak it into an obscure or unscrutinized piece of code in the hope it would go undetected. To defend against this, many organizations require peer code reviewing as part of their development processes. The idea is that if something fishy were added to the code, the peer reviewer would find and flag it before it merges with the production branch. But what if human reviewers can’t see the malicious code?
That’s exactly what the new Trojan Source (CVE-2021-42574) enables attackers to do—insert code that appears to humans as innocuous but is interpreted by compilers in a malicious way. It uses bidirectional Unicode variables that under normal circumstances enable things like right-to-left languages to be displayed in a left-to-right manner. In a Trojan Source attack, this capability is used to show legitimate-looking source code to humans, while leveraging different code and logic upon compiling. Sneaky, right?
Defending Against Trojan Source
To better protect themselves from Trojan Source-based software supply chain attacks, security teams should implement security and governance policies across their tooling. These would check for or disable the use of bidirectional Unicode variables that can render differently than they’re interpreted or compiled.
Very few organizations need, or even use, this feature. Hence, turning it off—or flagging its occurrence and blocking code commits that include its use—ensures that code can be properly peer-reviewed as part of standard branch protection.
The challenge is that code lives in so many places across an enterprise. Not only does it reside in multiple phases and tools across the SDLC, but modern enterprises also have multiple development teams leveraging multiple software delivery pipelines. Ensuring that any particular setting meets policy standards across an entire enterprise is challenging.
Implementing consistent and effective security policies across today’s diverse software development pipelines remains a challenge for security professionals. This includes those required to prevent this form of obfuscation and ensure peer code reviews remain effective. Consistent governance combined with the ability to ensure integrity and provenance across the SDLC can greatly reduce the likelihood of organizations experiencing software supply chain attacks.
Detecting Bidirectional Unicode Within Developer Workflows
In response to the Trojan Source attack, Cycode has added support for detecting Unicode bidirectional characters in its solution. Our customers can now automatically detect the use of such characters as part of their standard pull request flow. Moreover, customers can see if they’re using such character types in any of their repositories, enabling those found to be addressed in existing code bases. Ultimately, this lets reviewers detect any attempts to insert backdoors or malicious snippets using the Trojan Source method.

When a pull request is opened, Cycode comments on the occurrence of bidirectional characters and notifies the reviewer of their existence. This screenshot shows an example of what this looks like in Github.
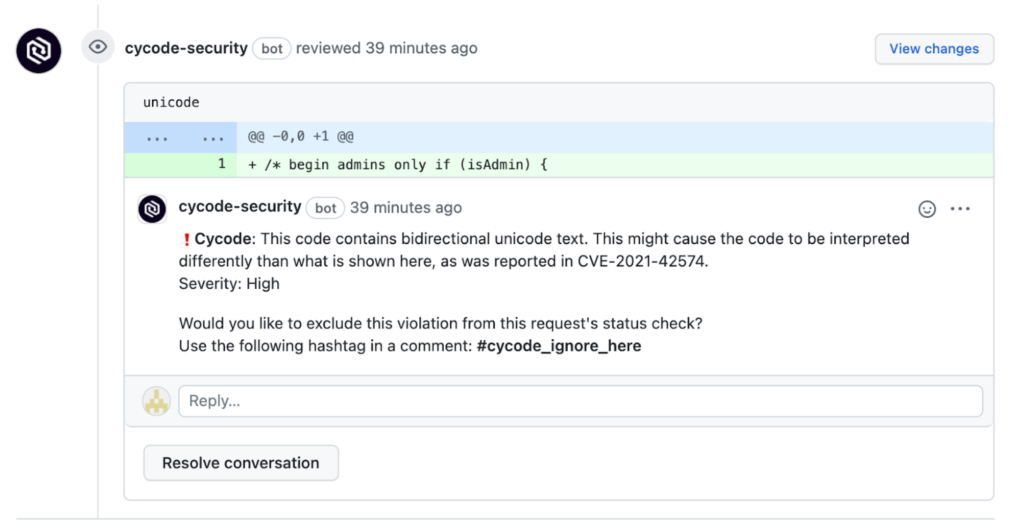
If bidirectional characters are found, Cycode alerts your developers and points them out directly in the code. From there the developers can determine how they want to handle the situation by commenting directly within the pull request. For example, they might wish to ignore an instance when it’s an appropriate situation to use bidirectional characters.
Those organizations wanting stronger controls can block bidirectional Unicode characters from entering their production branch. This works by scanning commits and merge requests for such characters and, upon a failed scan, blocking the commit or merge request in your SCM. Here’s what that looks like in Github:
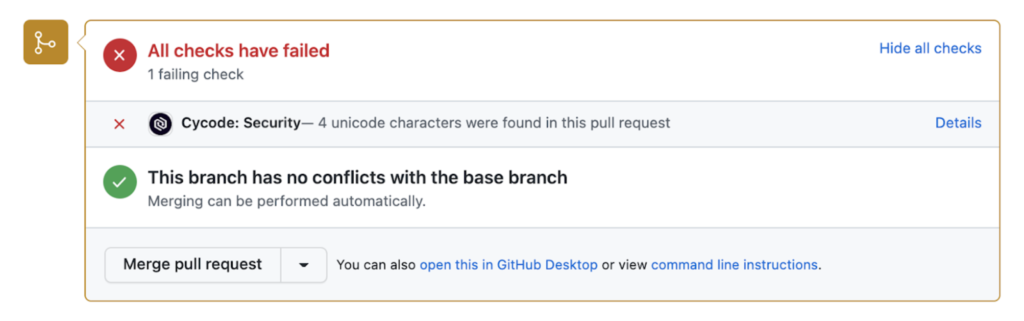
In conclusion, Cycode’s new capability provides organizations with 1) the ability to find potentially dangerous, bidirectional Unicode characters in their code and repos, 2) handle them in a way that works best for them, and 3) to do so within existing developer workflows so as not to impact developer efficiency.
Want to learn more about Cycode—or see if your repos have bidirectional characters in use?